

中大新聞中心
中大在生物序列分析領域取得新突破
香港中文大學(中大)工程學院在生物序列分析領域進行開創性研究,成功開發一項輔以人工智能技術(Artificial intelligence, AI)的密集同源物檢測技術(Dense Homolog Retriever, DHR)。這突破性技術能快速並準確地檢索蛋白質同源序列,有助提升探索蛋白質演變、結構和功能的能力,促進藥物開發和臨床療效。研究成果已於世界權威科學期刊《自然生物科技》發表,並於國際科學期刊《自然–方法》上刊登。
AI技術助DHR提升檢測效率及準確度
蛋白同源物檢測對了解其演變關係和預測蛋白質功能尤為重要。然而,傳統檢測方法主要依賴序列比對技術,如動態規劃演算法(例如BLAST及FASTA)。這些方法不但耗時,而且經常無法識別低序列相似度的遠端同源物,局限藥物開發和功能註釋所需的蛋白質網絡識別。
由中大工程學院計算機科學與工程學系助理教授李煜教授領導的研究團隊成功開發一項輔以AI技術的嶄新DHR方法,以解決計算生物學中長期存在的蛋白質同源檢測難題。有別於傳統方法,DHR建基於雙編碼器模型,並採用密集檢索及對比學習檢測同源關係。透過序列編碼為密集向量及利用點積計算與評估同源得分,DHR在速度和準確度均比傳統方法優勝。李教授表示:「DHR擅於發現傳統方法經常遺漏的遠端同源物,而且更快及更精確,非常適合在大型資料庫中探索蛋白質序列的多樣性。」
在人工智能應用日益普及的時代,大型語言模型已可執行上下文檢索,研究中DHR運用相似方法識別蛋白質同源物的效果理想。這研究項目旨在加快人工智能模型AlphaFold 2的同源物檢索速度,其透過傳統方法,成功與研究人員的流程中所採用的新方法相結合,令速度比以往快數十倍,擺脫瓶頸。中大研究團隊計劃創建一個開源且易於使用的工具,有助蛋白質分析更廣泛應用及帶動持續創新。
DHR助開發標靶治療及新抗生素
DHR檢測遠端同源物的功能為開發藥物開闢了新機遇。例如,在癌症研究中,它能夠識別令細胞生長和凋亡的蛋白質同源物,有助開發針對腫瘤生長或誘導癌細胞死亡的治療方法。
此外,DHR在對抗抗生素抗藥性具有重要價值,透過檢測在抗藥菌株中對細菌生存至關重要的保守蛋白質,有助研究人員開發新型抗生素,即使細菌演化仍然有效。
阿茲海默症及柏金遜症等神經退化性疾病涉及特定蛋白質的錯誤摺疊和聚集。透過檢測這些蛋白質的同源物,DHR有助理解相關疾病的分子機制,加快研究防止蛋白質錯誤摺疊,或去除有毒聚集物的新型療法,令病情有望放緩。
研究論文全文見:https://www.nature.com/articles/s41587-024-02353-6


中大工程學院計算機科學與工程學系助理教授李煜教授
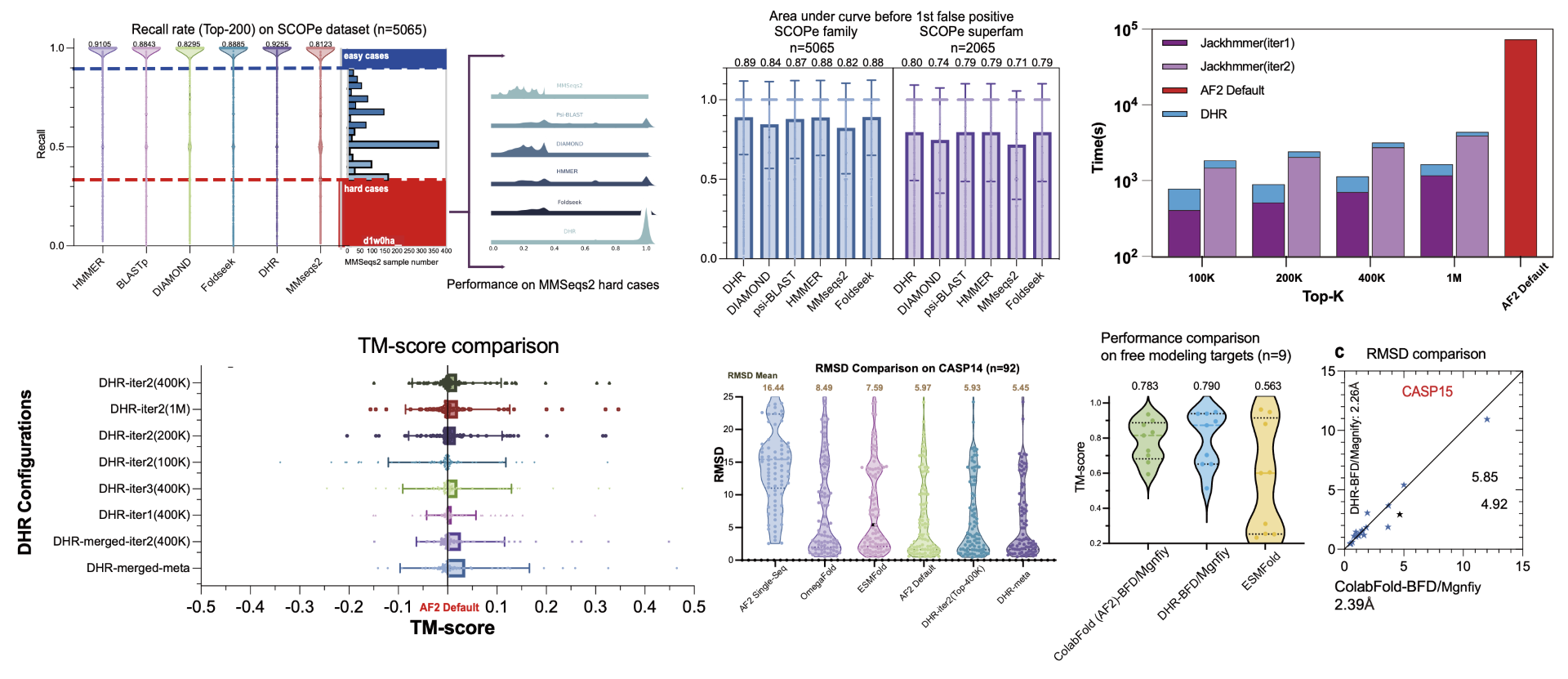
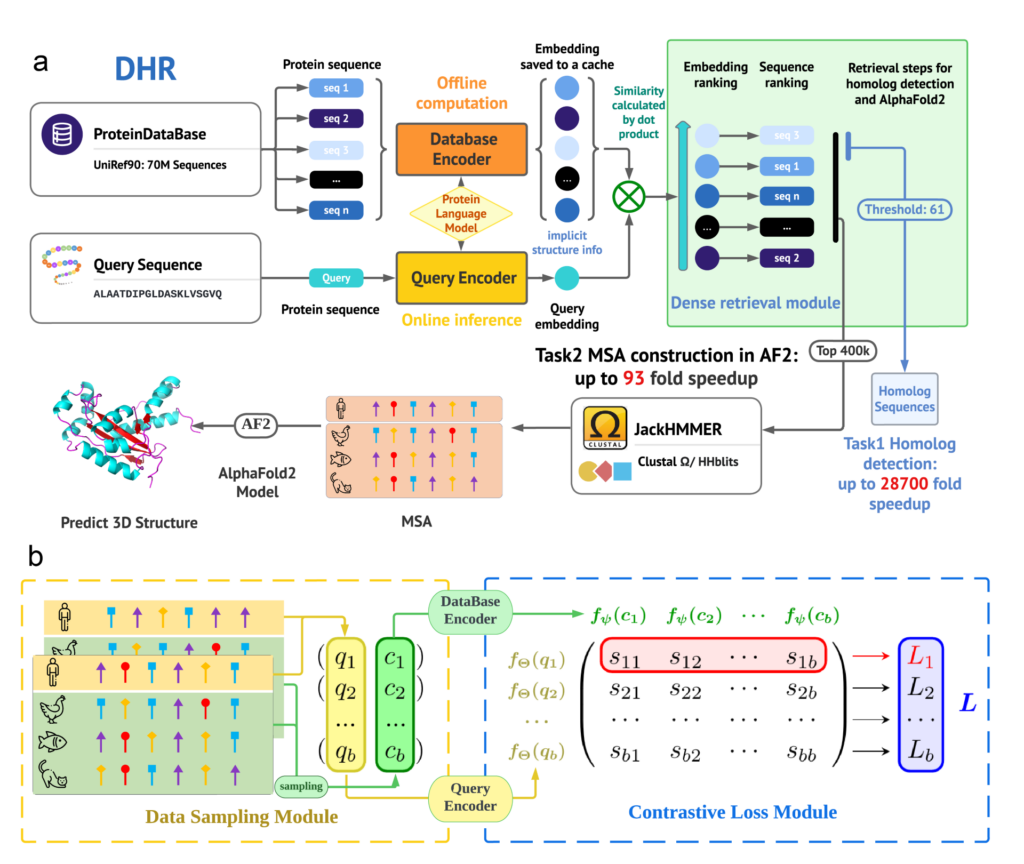
DHR 結果摘要: 在 SCOPe 數據集上的召回率,包括超家族層級的結果;在 CASP 數據集上與 JackHMMER 比較的平均執行時間效能,突顯效率的提升;以及使用 DHR 建立的 MSA 與預設 AlphaFold 2 結果比較的結構預測結果,顯示預測準確度的提升。
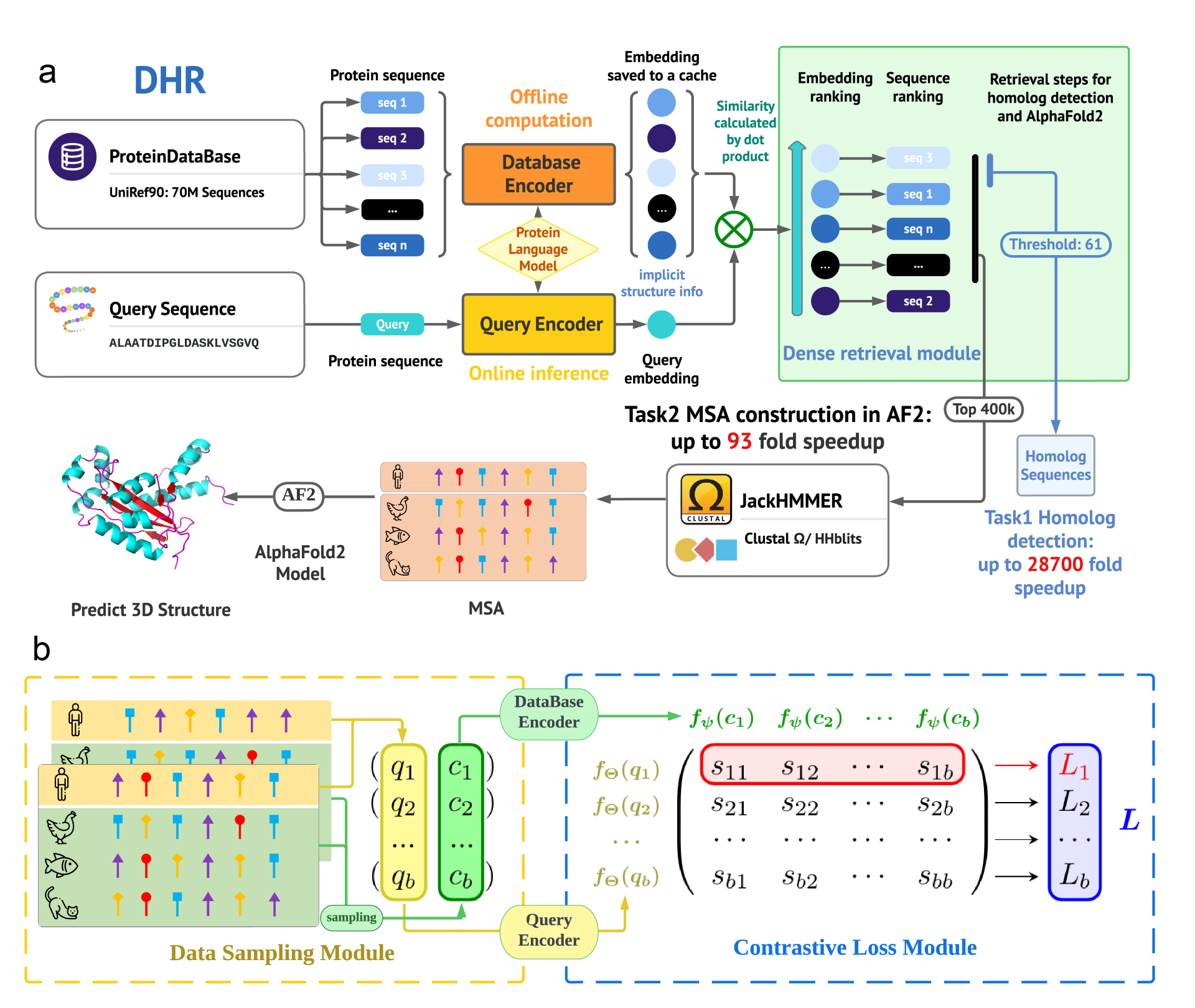
DHR 架構概述: 三層分層結構著重於訓練蛋白質資料庫編碼器和查詢編碼器。在蛋白質資料庫上使用快取內嵌進行離線推論,可有效率地進行向量層級的相似性計算,以排列序列。推論管道會使用點乘法擷取前 K 個最相關的序列。然後,JackHMMER 應用於此子集,以建構 MSA,用於 3D 結構預測或蛋白質功能預測等下游任務。UniRef90 可以離線編碼成向量,而不會影響 MSA 的建構速度。

